Large JSON in Python: Parser Speed Is Not the Whole Problem
A benchmark-driven look at why large JSON ingestion in Python is often more about memory shape than raw parser speed.
Large JSON ingestion in Python usually gets discussed as a parser-speed problem.
That is only part of it.
For large files, the bigger issue can be memory shape.
The normal code for a JSON array looks like this:
import json
with open("large_array.json") as f:
records = json.load(f)
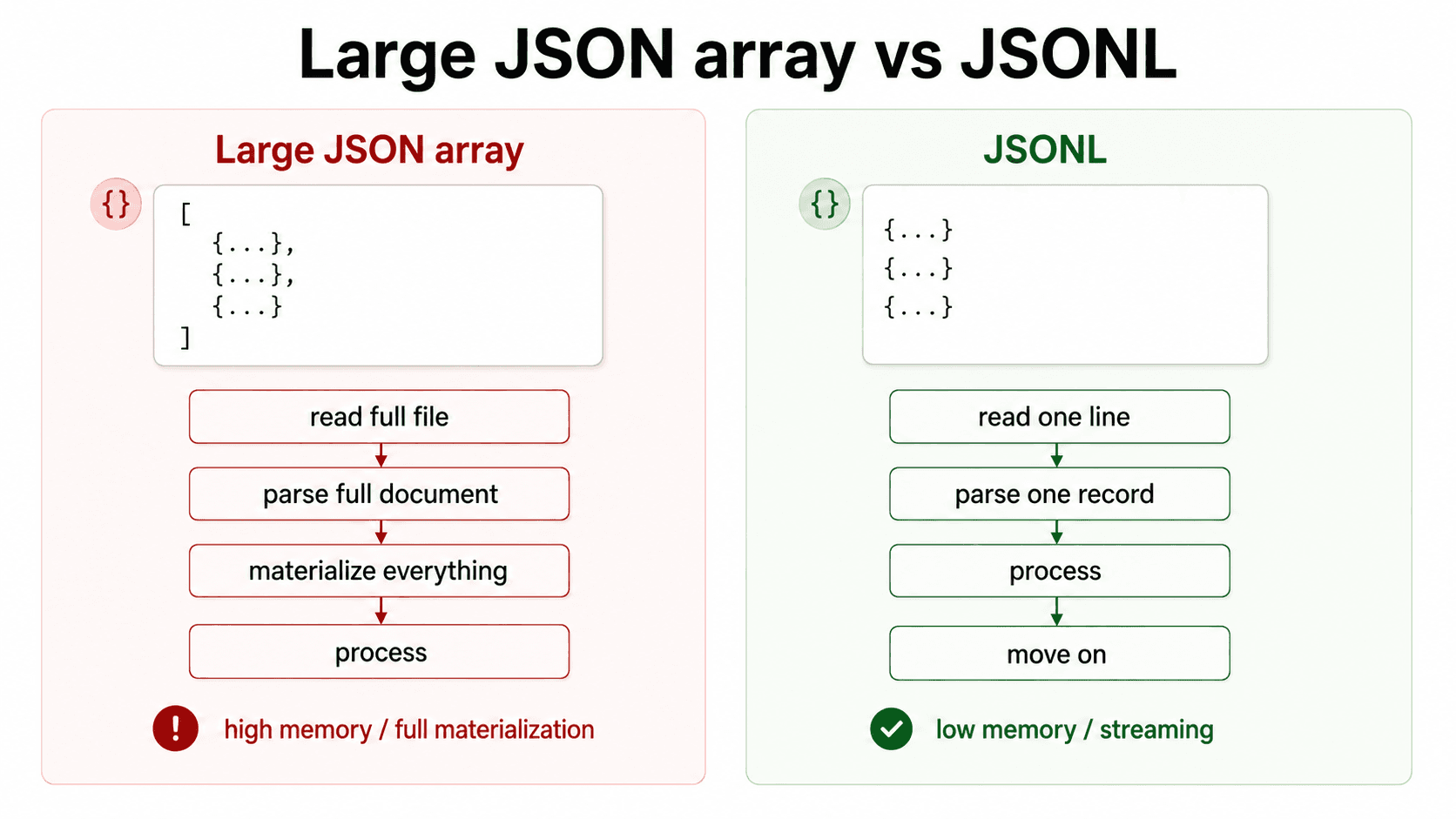
for record in records:
process(record)This is simple and fine for small files. But json.load() has to build the full Python object before useful processing starts.
So the real flow is:
- read the file
- parse the full JSON document
- create Python dict/list objects for everything
- then process records
For a large JSON array, that can become expensive before business logic even runs.
Setup
I ran the benchmark on an AWS EC2 m7i.xlarge instance.
| Detail | Value |
|---|---|
| Instance | AWS EC2 m7i.xlarge |
| Region | ap-south-1 |
| Python | 3.13.13 |
| CPU | 4 vCPU, Intel Xeon Platinum 8488C |
| Memory | 15 GiB |
| Root disk | 48 GiB |
| Records | 2,000,000 |
| Input shapes | JSON array and JSONL |
| Parsers | Python json and simdjson |
The goal was not to create a perfect benchmark. The goal was to compare the processing shape:
- full JSON array materialized in memory
- JSONL streamed one record at a time
The exact numbers will vary with schema, CPU, disk cache, parser version, and the work done in process(). The important signal here is the difference between full materialization and streaming.
Files
I generated two files with the same kind of synthetic event data.
One file was a single large JSON array:
[
{"id": 1, "event_type": "search"},
{"id": 2, "event_type": "upload"},
{"id": 3, "event_type": "ask_ai"}
]The other file was JSONL:
{"id": 1, "event_type": "search"}
{"id": 2, "event_type": "upload"}
{"id": 3, "event_type": "ask_ai"}JSONL is less fancy, but it is easier to process incrementally.
$ tree --du -h
[1.6G] .
├── [822M] large_array.json
└── [820M] large_events.jsonl
1.6G used in 1 directory, 2 filesThe files are roughly the same size on disk. The large difference shows up during processing, when one path materializes the full array and the other keeps memory flat.
Methods Compared
I compared four methods:
json_load_arraysimdjson_load_arrayjsonl_stdlib_streamjsonl_simdjson_stream
The benchmark measured:
- records processed
- time taken
- records per second
- peak RSS memory
Result
This was the result from the EC2 run:
| Method | Records | Time seconds | Records per second | Peak RSS MB |
|---|---|---|---|---|
json_load_array | 2,000,000 | 5.901 | 338,899 | 3457.62 |
simdjson_load_array | 2,000,000 | 6.451 | 310,017 | 7367.77 |
jsonl_stdlib_stream | 2,000,000 | 5.381 | 371,672 | 24.69 |
jsonl_simdjson_stream | 2,000,000 | 2.832 | 706,249 | 24.94 |
The JSONL streaming versions stayed around 25 MB peak RSS.
The full-array versions used multiple GB.
simdjson was fastest in the JSONL streaming case. But the full-array simdjson version still had high memory usage because the code parsed the full file and converted it into Python objects with recursive=True.
That is the point.
A faster parser helps when parsing is the bottleneck. It does not automatically fix a pipeline that materializes too much data at once.
Code Difference
The full-array version:
def method_json_load_array(path):
with path.open("r", encoding="utf-8") as f:
records = json.load(f)
total = 0
for record in records:
process(record)
total += 1
return totalThe important detail is this line:
records = json.load(f)At that point, the full parsed structure exists in memory.
The JSONL streaming version:
def method_jsonl_stdlib_stream(path):
total = 0
with path.open("r", encoding="utf-8") as f:
for line in f:
record = json.loads(line)
process(record)
total += 1
return totalHere, the program only needs one record at a time.
What I Would Check First
For large ingestion jobs, I would not start with:
Which parser is fastest?
I would start with:
Do we need to load all of this at once?
The questions I would check first:
- Can the producer send JSONL?
- Can we process records in batches?
- Can we checkpoint progress?
- Can failed batches be retried?
- Can output be written incrementally?
- Do we need the full document in memory?
Parser choice still matters. But the data shape decides how predictable the system is.
Why JSONL Works Well for Ingestion
JSONL is boring.
That is why it works well.
Each line is one record. That makes it easier to:
- stream records
- batch writes
- checkpoint progress
- retry failed batches
- resume processing
- split files
- process in workers
- keep memory stable
A single huge JSON array is easier to pass around as one object. But once the file becomes large, it is harder to operate.
Code
The benchmark code is available on GitHub.
Takeaway
For large JSON ingestion in Python, parser speed is only part of the problem.
The bigger question is the processing shape.
A faster parser can reduce parse time. But predictable memory usage usually comes from not loading everything at once.
For large files, I would rather have a boring pipeline that streams records, writes in batches, checkpoints progress, and can be retried safely.
Fast is good.
Predictable is better.